

Calibration
The user adjust the translation and rotation of the virtual coordinate system such that it can align with the pre-defined TCP position (the white sphere) and the origin of the world coordinate system.
Humans can accomplish complex contact-rich tasks using vision and touch, with highly reactive capabilities such as quick adjustments to environmental changes and adaptive control of contact forces; however, this remains challenging for robots. Existing visual imitation learning (IL) approaches rely on action chunking to model complex behaviors, which lacks the ability to respond instantly to real-time tactile feedback during the chunk execution. Furthermore, most teleoperation systems struggle to provide fine-grained tactile / force feedback, which limits the range of tasks that can be performed.
To address these challenges, we introduce TactAR,
a low-cost teleoperation system that provides real-time tactile feedback through Augmented Reality (AR),
along with Reactive Diffusion Policy (RDP),
a novel slow-fast visual-tactile imitation learning algorithm for learning contact-rich manipulation skills.
RDP employs a two-level hierarchy:
(1) a slow latent diffusion policy for predicting high-level action chunks in latent space at low frequency,
(2) a fast asymmetric tokenizer for closed-loop tactile feedback control at high frequency.
This design enables both complex trajectory modeling and quick reactive behavior within a unified framework.
Through extensive evaluation across three challenging contact-rich tasks, RDP significantly improves performance compared to state-of-the-art visual IL baselines through rapid response to tactile / force feedback. Furthermore, experiments show that RDP is applicable across different tactile / force sensors.

Fig. 1: The motivation of this project is to combine the advantages of low-frequency visual imitation learning (IL) and high-frequency tactile / force controller. We use a slow network which acts like a neural planner for predicting high-level action chunks, while using a fast network which acts like a learnable impedance controller for finetuning the latent action chunks based with tactile / force feedback.
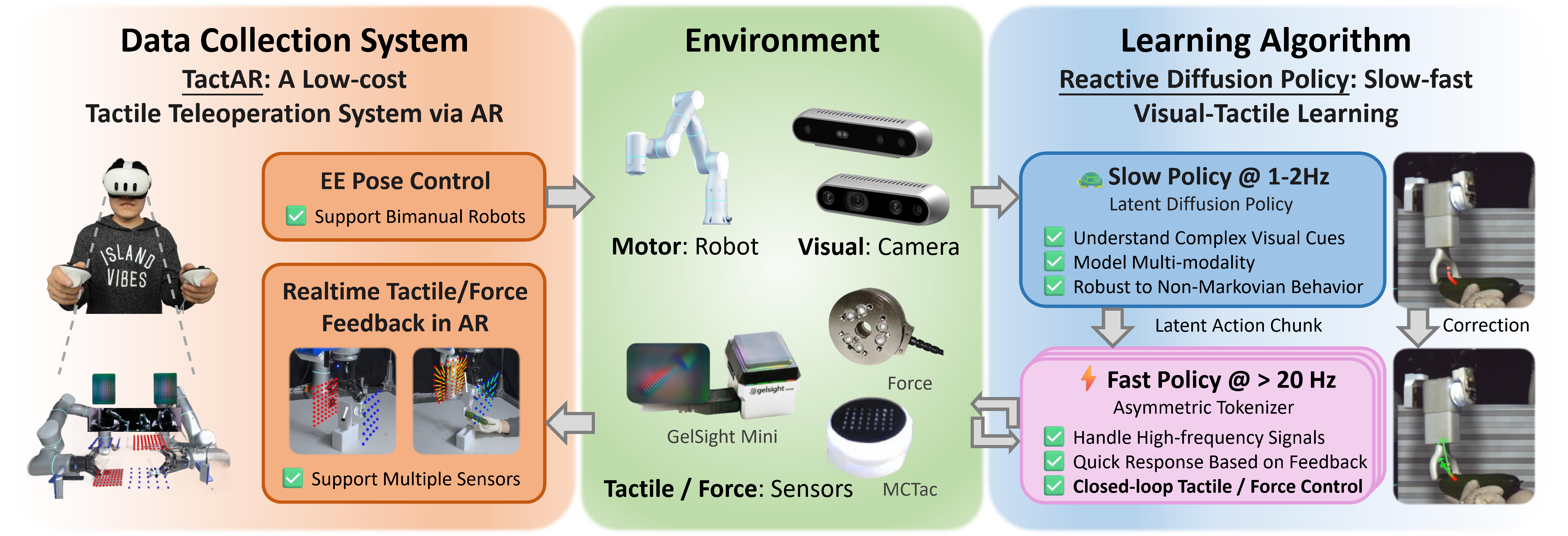
Fig. 2: TactAR is a low-cost and versatile teleoperation system which can provide real-time tactile / force feedback via Augmented Reality (AR). Reactive Diffusion Policy (RDP) is a slow-fast imitation learning algorithm that can model complex behaviors with a slow policy network and achieve closed-loop control based on tactile / force feedback with a fast policy network.

Fig. 3: Overview of TactAR teleoperation system. It can provide real-time tactile / force feedback via Augmented Reality (AR). The tactile feedback is represented as the 3D deformation field, which is a universal representation applicable to multiple different tactile / force sensors. The 3D deformation field is rendered and "attached" to the robot end-effector in AR, which makes the user perceive the rich contact information in 3D space. TactAR also support real-time streaming for multiple RGB cameras and optical tactile sensors.
The user adjust the translation and rotation of the virtual coordinate system such that it can align with the pre-defined TCP position (the white sphere) and the origin of the world coordinate system.
The 3D deformation / force field of the tactile / force sensors can be rendered in real time with Augmented Reality (AR).
The 3D deformation field is attached to the robot end-effector in virtual space.
The system supports real-time streaming of multi-view RGB cameras and tactile cameras for more immersive teleoperation experience.
When collecting contact-rich task data through teleoperation, the system can provide intuitive tactile / force information.

Fig. 4: Overview of Reactive Diffusion Policy (RDP) framework. (a) The training pipeline of RDP, comprising the first stage for training the fast policy (Asymmetric Tokenizer) and the second stage for training the slow policy (Latent Diffusion Policy). (b) The inference pipeline of RDP. The slow policy leverages low-frequency observations for modeling complex behaviors with diffusion and action chunking. The fast policy enables closed-loop control by using high-frequency tactile / force input and fine-tuning the latent action chunk predicted by the slow policy in an auto-regressive manner.

Fig. 5: Comparison among various pipelines. (a) Vanilla action chunking with open-loop control during the chunk execution. (b) Action chunking enhanced with temporal ensembling for semi-closed-loop control. (c) Our slow-fast inference pipeline, showcasing closed-loop capabilities with fast responsive adjustments. (d) Human control patterns in contact-rich tasks.
Table I: The inference time of the slow / fast policy of RDP compared with Diffusion Policy measured on RTX 4090. The results show that our fast policy can achieve an inference speed of less than 1 ms, enabling real-time closed-loop control.
| Diffusion Policy | Slow Policy (LDP) | Fast Policy (AT) |
|---|---|---|
| 120ms | 100ms | \(\lt\) 1ms |
Task Description: The robot needs to grasp the peeler, approach a cucumber held midair by a human hand, then begin peeling. This task requires the following capabilities: (1) Precision. The robot needs to finish the task under environment uncertainties (e.g., different tool grasp locations, different cucumber pose) with high precision (millimeter-level). (2) Fast response. The robot needs to react instantly to human perturbations.
Evaluation Protocol: There are three test-time variations and we run 10 trials for each variation: (1) No perturbation. The object is fixed with a random 6D pose in the air. (2) Perturbation before contact. The human evaluator will move the object right before the tool makes contact. (3) Perturbation after contact. The human evaluator will move the object after the tool makes contact to break the contact state.
Score Metric: We calculate the score based on the proportion of the peeled cucumber skin to the total length of the cucumber, normalized by the average score of the demonstration data.
TABLE II: Policy Performance for Peeling Task
| No Perturb. | Perturb. before Contact | Perturb. after Contact | All | |
|---|---|---|---|---|
| DP | 0.56 | 0.58 | 0.19 | 0.44 |
| DP w. tactile img. | 0.60 | 0.49 | 0.16 | 0.41 |
| DP w. tactile emb. | 0.48 | 0.55 | 0.15 | 0.39 |
| RDP (GelSight) | 0.98 | 0.93 | 0.80 | 0.90 |
| RDP (MCTac) | 1.00 | 0.84 | 0.79 | 0.88 |
| RDP (Force) | 0.99 | 0.98 | 0.88 | 0.95 |
Video of all trials:
Task Description: The robot needs to grasp the eraser, approach the vase held midair by a human hand, then begin wiping. This task requires the following capabilities: (1) Adaptive force control with rotation. The robot needs to adaptively track the curved vape surface with different environment uncertainties (e.g., tool grasp locations, vase pose). (2) Fast response. The robot needs to react instantly to human perturbations.
Evaluation Protocol: The same as Task1: Peeling.
Score Metric: We calculate the score based on the size of the remaining handwriting compared to the demonstration data. If the residue reaches the human demonstration level, the score is 1; If there is minor residue (less than one third of the handwriting length), the score is 0.5; If significant residue remains, the score is 0.
TABLE III: Policy Performance for Wiping Task
| No Perturb. | Perturb. before Contact | Perturb. after Contact | All | |
|---|---|---|---|---|
| DP | 0.75 | 0.70 | 0.25 | 0.57 |
| DP w. tactile emb. | 0.60 | 0.75 | 0.15 | 0.50 |
| RDP (GelSight) | 0.85 | 0.95 | 0.50 | 0.77 |
| RDP (Force) | 0.95 | 0.85 | 0.80 | 0.87 |
Video of all trials:
Task Description: The two robot arms need to grasp the handlers, approach the paper cup, clamp the paper cup with the two handlers, carefully lift the cup along the trajectory of the curve without squeezing it. This task requires the following capabilities: (1) Precise force control. The two robots must apply precise force during the task execution. It is crucial to avoid exerting excessive force that could squeeze the cup while also ensuring that the force is sufficient to prevent the cup from slipping. (2) Bimanual coordination. (3) Multi-modality. In the expert data, there are two upward lift trajectories.
Evaluation Protocol: There are two test-time variations and we run 10 trials for each variation: (1) soft paper cup. (2) hard paper cup.
Score Metric: If the paper cup is lifted into the air following the designated trajectory without significant compression, the score will be 1; If the paper cup is partially compressed in the air, the score will be 0.5; If the cup is not lifted up, or dropped in the air, the score will be 0.
TABLE IV: Policy Performance for Bimanual Lifting Task
| Soft Paper Cup | Hard Paper Cup | All | |||||
|---|---|---|---|---|---|---|---|
| Clamp | Lift | Score | Clamp | Lift | Score | Score | |
| DP | 0% | 0% | 0.00 | 0% | 0% | 0.00 | 0.00 |
| DP w. tactile emb. | 10% | 10% | 0.10 | 20% | 10% | 0.05 | 0.08 |
| RDP (GelSight + MCTac) | 100% | 100% | 0.55 | 90% | 80% | 0.40 | 0.48 |
| RDP (Force) | 100% | 90% | 0.80 | 90% | 90% | 0.60 | 0.70 |
Video of all trials:
We visualize the original action predicted by the slow policy (red and blue dots) and the corrected action (green dots) predicted with tactile feedback by the fast network. The results show that the fast policy can utilize tactile information to achieve quick and accurate responses, thereby completing contact-rich tasks smoothly.
We obtain the original action through padding the initial tactile / force signal. The corrected action has been scaled up to achieve clearer visual effects.
DP w. tactile emb.
DP w. tactile emb.
DP w. tactile img.
DP
DP w. tactile emb. (temp. ens., \( \tau = 0.8 \))
DP w. tactile emb.
DP w. tactile emb. (chunk size \(= 2\))
DP w. tactile emb.
We conduct a user study and collect data from different teleoperation methods to investigate how tactile / force feedback in TactAR contributes to data quality and policy performance.
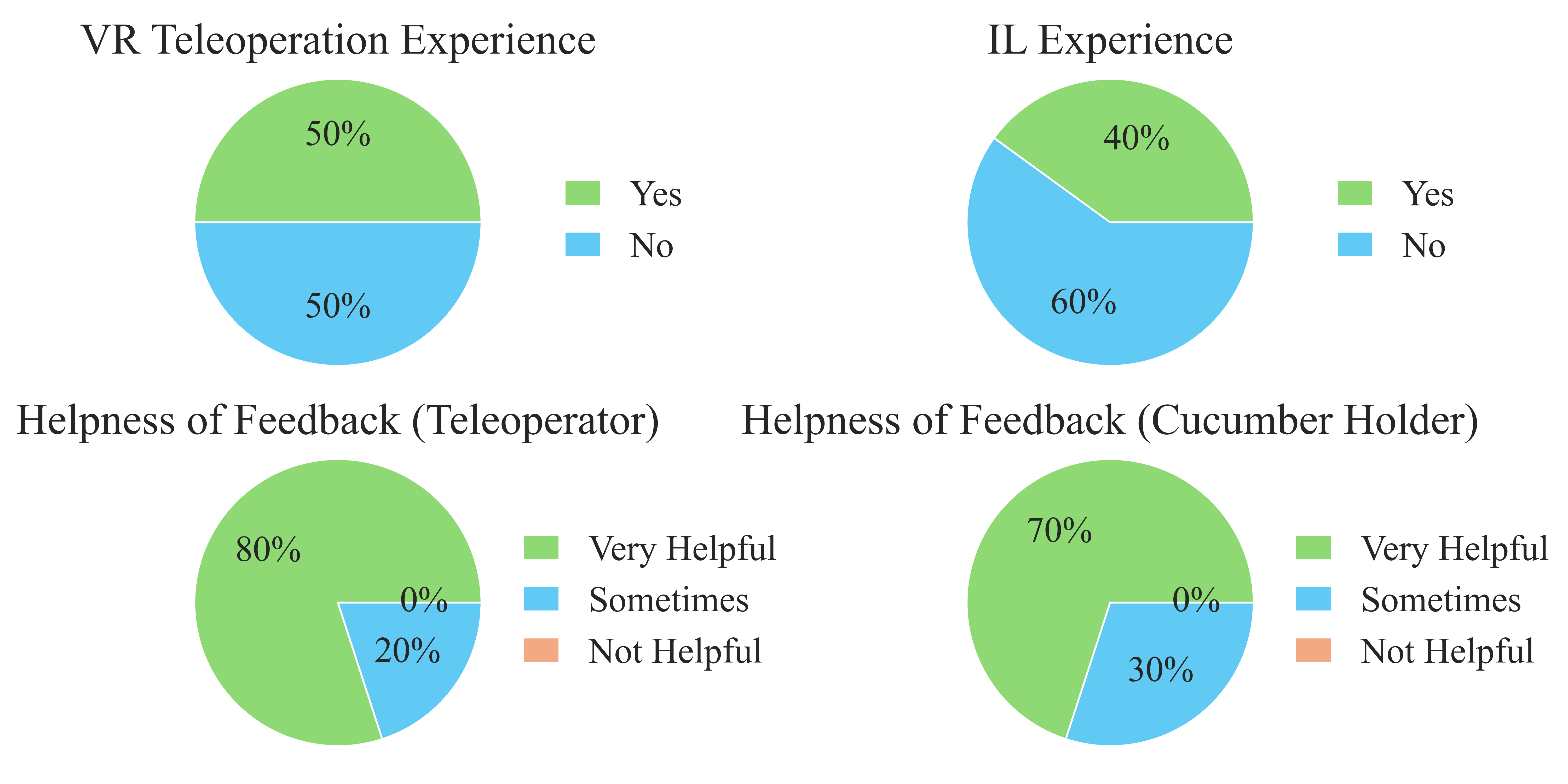
Fig. 6: We conduct a user study involving 10 users with different levels of experience in VR teleoperation or Imitation Learning (IL). Each pair of users participate in the experiments on the Peeling task, whereby one user teleoperate the robotic arm to peel a cucumber and the other held the cucumber. The teleoperator is subjected to two distinct settings: traditional VR teleoperation and TactAR. The result indicates that most of the users (\(\ge\) 70%) found that tactile / force AR feedback is very helpful in data collection, regardless of whether they were acting as the teleoperator or the person holding the cucumber.
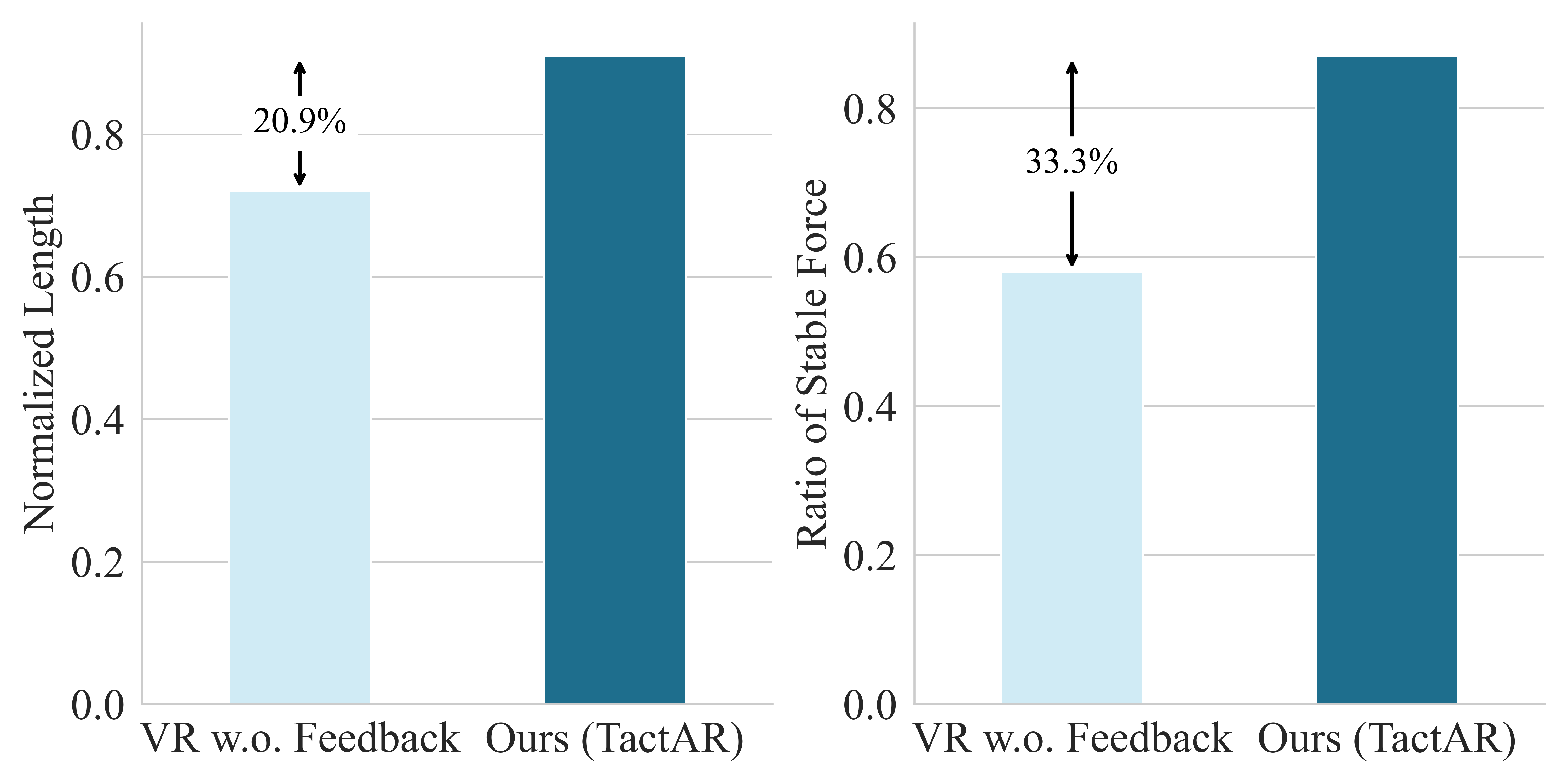
Fig. 7: During the user study, each user conducts 10 trials for traditional teleoperation and TactAR, respectively. We record the length of the cucumber peel obtained in each trial and assess whether the force applied by the robotic arm was consistently stable from the perspective of the user holding the cucumber. The result shows that tactile / force feedback in TactAR can greatly improve the data quality from both the normalized peeling length (0.72 \(\rightarrow\) 0.91) and the ratio of stable contact force (0.58 \(\rightarrow\) 0.87).
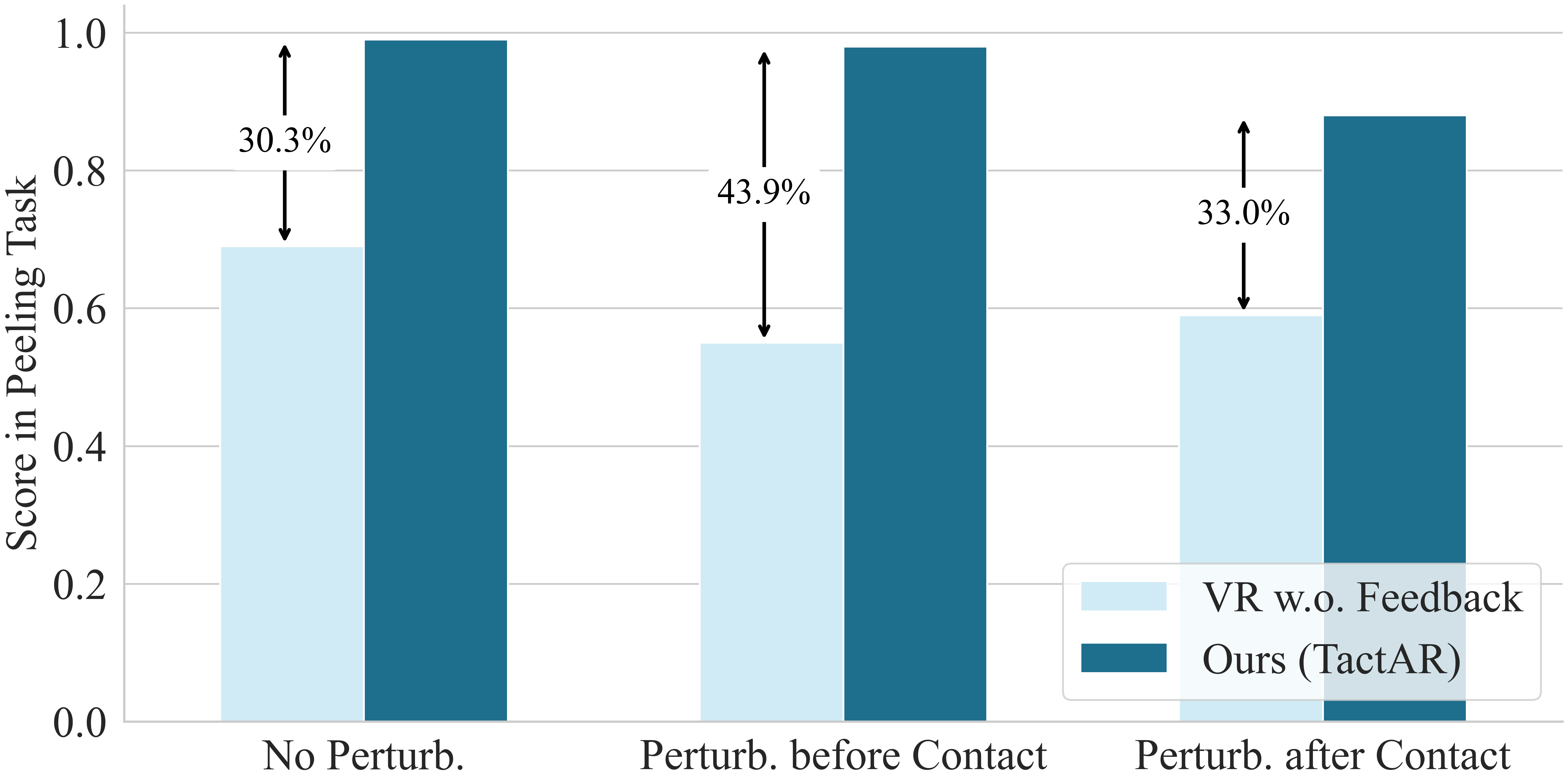
Fig. 8: We collect the same number of demonstrations (60) for Peeling task with traditional VR teleoperation without tactile / force feedback and train RDP (force) with these data. The result demonstrates that data quality has a large influence on policy performance (the score decreases by more than 30%). We observe that policies trained with low-quality data exhibited more unstable performance, such as more unstable force during peeling and a higher likelihood of breaking halfway through. A possible explanation is that the Fast Policy in RDP is designed to identify associations between tactile / force signals and trajectories from the data and learn reactive behavior. When contact forces in the data are highly unstable, the Fast Policy struggles to identify reasonable associations, which reduces performance.
@inproceedings{xue2025reactive,
title = {Reactive Diffusion Policy: Slow-Fast Visual-Tactile Policy Learning for Contact-Rich Manipulation},
author = {Xue, Han and Ren, Jieji and Chen, Wendi and Zhang, Gu and Fang, Yuan and Gu, Guoying and Xu, Huazhe and Lu, Cewu},
booktitle = {Proceedings of Robotics: Science and Systems (RSS)},
year = {2025}
}
@article{chen2025implicitrdp,
title = {ImplicitRDP: An End-to-End Visual-Force Diffusion Policy with Structural Slow-Fast Learning},
author = {Chen, Wendi and Xue, Han and Wang, Yi and Zhou, Fangyuan and Lv, Jun and Jin, Yang and Tang, Shirun and Wen, Chuan and Lu, Cewu},
journal = {arXiv preprint arXiv:2512.10946},
year = {2025}
}